# Evaluate an LLM response
Building production-ready and reliable AI applications requires safeguards provided by an evaluation layer. LLM responses can vary drastically based on even the slightest input changes.
Scorable provides a robust set of fundamental evaluators suitable for any LLM-based application.
### Setup
You need a few examples of LLM outputs (text). Those can be from any source, such as a summarization output on a given topic.
### Running an evaluator through the UI
[The evaluators listing page](https://scorable.ai/skills/evaluators) shows all evaluators at your disposal. Scorable provides the base evaluators, but you can also build custom evaluators for specific needs.
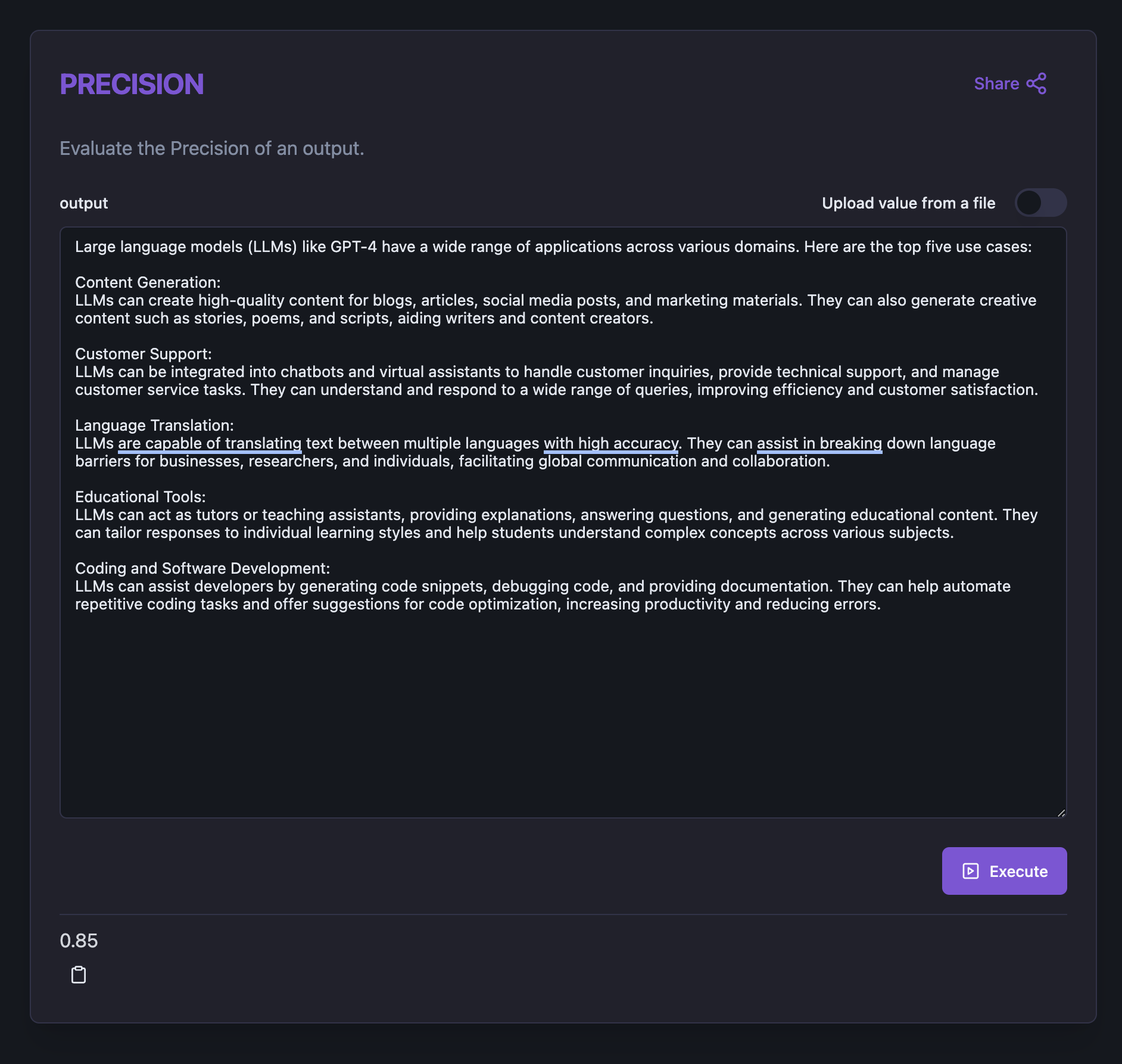
Let's start with the ***Precision*** evaluator. Based on the text you want to evaluate, feel free to try other evaluators as well.
1. Click on the ***Precision*** evaluator and then click on the *Execute skill* button.
2. Paste the text you want to evaluate into the output field and click *Execute*. You will get a numeric score based on the metric the evaluator is evaluating and the text to evaluate.
Evaluator result 0.85 for the text summarizing LLM use-cases.
An individual score is not very interesting. The power of evaluation lies in integrating evaluators into an LLM application.
### Integrating evaluators as part of existing AI automation
Integrating the evaluators as part of your LLM application is a more systematic approach to evaluating LLM outputs. That way, you can compare the scores over time and take action based on the evaluation results.
The ***Precision*** evaluator details page contains information on how to add it to your application. First, you must fetch a Scorable API key and then execute the example cURL command.
1. Go to the ***Precision*** evaluator details page
2. Click on the *Add to your application* link
3. Copy the cURL command
You can omit the `request` field from the data payload and add the text to evaluate in the `response` field.\
\
**Example (cURL)**
```bash
curl 'https://api.scorable.ai/v1/skills/evaluator/execute/767bdd49-5f8c-48ca-8324-dfd6be7f8a79/' \
-H 'authorization: Api-Key ' \
-H 'content-type: application/json' \
--data-raw '{"response":"While large language models (LLMs) have many powerful applications, there are scenarios where they are not as effective or suitable. Here are some use cases where LLMs may not be useful:\n\nReal-Time Critical Systems:\nLLMs are not ideal for applications requiring real-time, critical decision-making, such as air traffic control, medical emergency systems, or autonomous vehicle navigation, where delays or errors can have severe consequences.\n\nHighly Specialized Expert Tasks:\nTasks that require deep domain-specific expertise, such as advanced scientific research, complex legal analysis, or detailed medical diagnosis, may be beyond the capabilities of LLMs due to the need for precise, highly specialized knowledge and judgment."}'
```
#### Example (Python SDK)
```python
# pip install scorable
from scorable import Scorable
client = Scorable(api_key="")
client.evaluators.Precision(
response="While large language models (LLMs) have many powerful applications, there are scenarios where they are not as effective or suitable. Here are some use cases where LLMs may not be useful:\n\nReal-Time Critical Systems:\nLLMs are not ideal for applications requiring real-time, critical decision-making, such as air traffic control, medical emergency systems, or autonomous vehicle navigation, where delays or errors can have severe consequences.\n\nHighly Specialized Expert Tasks:\nTasks that require deep domain-specific expertise, such as advanced scientific research, complex legal analysis, or detailed medical diagnosis, may be beyond the capabilities of LLMs due to the need for precise, highly specialized knowledge and judgment."
)
```
### Evaluating Multi-Turn Conversations
You can provide message history containing the full interaction, including tool calls:
```python
from scorable import Scorable
from scorable.multiturn import Turn
client = Scorable(api_key="")
# Create a multi-turn conversation
turns = [
Turn(role="user", content="Hello, I need help with my order"),
Turn(role="assistant", content="I'd be happy to help! What's your order number?"),
Turn(role="user", content="It's ORDER-12345"),
Turn(
# Assistant turn can be a tool call which may not be directly visible to the user.
role="assistant",
content="{'order_number': 'ORDER-12345', 'status': 'shipped', 'eta': 'Jan 20'}",
tool_name="order_lookup",
),
Turn(
role="assistant",
content="I found your order. It's currently in transit.",
),
]
# Evaluate the multi-turn conversation
result = client.evaluators.Helpfulness(turns=turns)
print(f"Score: {result.score}")
print(f"Justification: {result.justification}")
```